|

- UID
- 1029342
- –‘±π
- Ρ–
|

CPU”κΡΎ¥φΒΡΡ«–© ¬
| ±ΨΈΡ“‘“ΜΗωœ÷¥ζΒΡΓΔ ΒΦ ΒΡΗω»ΥΒγΡ‘ΈΣΕ‘œσΘ§Ζ÷ΈωΤδ÷–CPUΘ®Intel Core 2 Duo 3.0GHzΘ©“‘ΦΑΗςάύΉ”œΒΆ≥ΒΡ‘Υ––ΥΌΕ»ΓΣΓΣ―”≥ΌΚΆ ΐΨίΆΧΆ¬ΝΩΓΘΆ®Ιΐ¥÷¬‘ΒΡΙάΥψPCΗςΗωΉιΦΰΒΡœύΕ‘‘Υ––ΥΌΕ»Θ§œΘΆϊΡήΗχ¥σΦ“Ντœ¬“ΜΗω±»Ϋœ÷±ΙέΒΡ”ΓœσΓΘ±ΨΈΡ÷–ΒΡ ΐΨίά¥Ή‘ ΒΦ ”Π”ΟΘ§ΕχΖ«άμ¬έΉν¥σ÷ΒΓΘ ±ΦδΒΡΒΞΈΜ «Ρ…ΟκΘ®nsΘ§ °“ΎΖ÷÷°“ΜΟκΘ©Θ§ΚΝΟκΘ®msΘ§«ßΖ÷÷°“ΜΟκΘ©Θ§ΚΆΟκΘ®sΘ©ΓΘΆΧΆ¬ΝΩΒΡΒΞΈΜ «’ΉΉ÷ΫΎΘ®MBΘ©ΚΆ«ß’ΉΉ÷ΫΎΘ®GBΘ©ΓΘ»ΟΈ“Ο«œ»¥”CPUΚΆΡΎ¥φΩΣ ΦΘ§œ¬ΆΦ «±±«≈≤ΩΖ÷ΘΚ 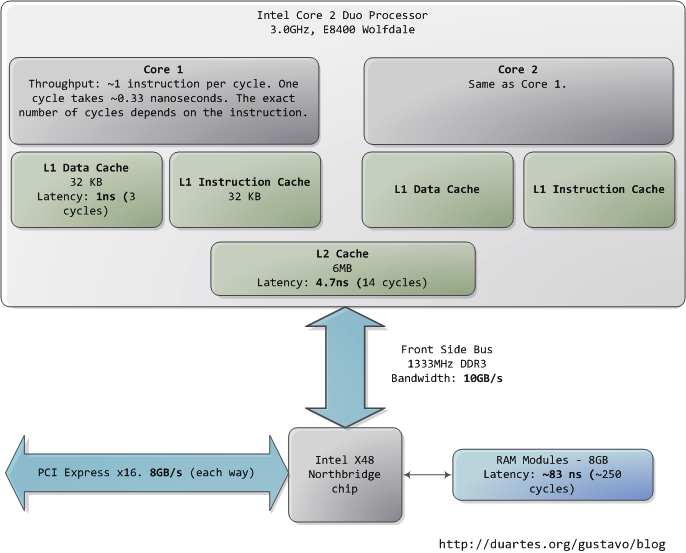
ΒΎ“ΜΗωΝν»ΥΨΣΧΨΒΡ ¬ Β «ΘΚCPUΩλΒΟάκΤΉΓΘ‘ΎCore 2 3.0GHz…œΘ§¥σ≤ΩΖ÷ΦρΒΞ÷ΗΝνΒΡ÷¥––÷Μ–η“Σ“ΜΗω ±÷”÷ήΤΎΘ§“≤ΨΆ «1/3Ρ…ΟκΓΘΦ¥ Ι «’φΩ’÷–¥Ϊ≤ΞΒΡΙβΘ§‘Ύ’βΕΈ ±ΦδΡΎ“≤÷ΜΡήΉΏ10άεΟΉΘ®‘Φ4”Δ¥γΘ©ΓΘΑ―…œ ω ¬ ΒΦ«‘Ύ–Ρ÷– «”–ΚΟ¥ΠΒΡΓΘΒ±Ρψ“ΣΕ‘≥Χ–ρΉω”≈Μ·ΒΡ ±ΚρΨΆΜαœκΒΫΘ§÷¥––÷ΗΝνΒΡΩΣœζΕ‘”ΎΒ±ΫώΒΡCPUΕχ―‘ «ΕύΟ¥ΒΡΈΔ≤ΜΉψΒάΓΘ
Β±CPU‘ΥΉΣΤπά¥“‘ΚσΘ§Υϋ±ψΜαΆ®ΙΐL1 cacheΚΆL2 cacheΕ‘œΒΆ≥÷–ΒΡ÷ς¥φΫχ––ΕΝ–¥ΖΟΈ ΓΘcache Ι”ΟΒΡ «Ψ≤Χ§¥φ¥ΔΤς(SRAM)ΓΘœύΕ‘”ΎœΒΆ≥÷ς¥φ÷– Ι”ΟΒΡΕ·Χ§¥φ¥ΔΤςΘ®DRAMΘ©Θ§cacheΕΝ–¥ΥΌΕ»ΩλΒΟΕύΓΔ‘λΦέ“≤ΗΏΑΚΒΟΕύΓΘcache“ΜΑψ±ΜΖ≈÷Ο‘ΎCPU–ΨΤ§ΒΡΡΎ≤ΩΘ§Φ”÷° Ι”ΟΑΚΙσΗΏΥΌΒΡ¥φ¥ΔΤςΘ§ ΙΤδΗχCPU¥χά¥ΒΡ―”≥ΌΖ«≥ΘΒΆΓΘ‘Ύ÷ΗΝν≤ψ¥Έ…œΒΡ”≈Μ·Θ®instruction-level optimizationΘ©Θ§Τδ–ßΙϊ «”κ”≈Μ·Κσ¥ζ¬κΒΡ¥σ–ΓœΔœΔœύΙΊΓΘ”…”Ύ Ι”ΟΝΥΗΏΥΌΜΚ¥φΦΦ θΘ®cachingΘ©Θ§Ρ«–©ΡήΙΜ’ϊΧεΖ≈»κL1/L2 cache÷–ΒΡ¥ζ¬κΘ§ΚΆΡ«–©‘Ύ‘Υ–– ±–η“Σ≤ΜΕœΒς»κ/Βς≥ωΘ®marshall into/out ofΘ©cacheΒΡ¥ζ¬κΘ§‘Ύ–‘Ρή…œΜα≤ζ…ζΖ«≥ΘΟςœ‘ΒΡ≤ν“λΓΘ
’ΐ≥Θ«ιΩωœ¬Θ§Β±CPU≤ΌΉς“ΜΩιΡΎ¥φ«χ”ρ ±Θ§Τδ÷–ΒΡ–≈œΔ“ΣΟ¥“―Ψ≠±Θ¥φ‘ΎL1/L2 cacheΘ§“ΣΟ¥ΨΆ–η“ΣΫΪ÷°¥”œΒΆ≥÷ς¥φ÷–Βς»κcacheΘ§»ΜΚσ‘Ό¥ΠάμΓΘ»γΙϊ «Κσ“Μ÷÷«ιΩωΘ§Έ“Ο«ΨΆ≈ωΒΫΝΥΒΎ“ΜΗωΤΩΨ±Θ§“ΜΗω¥σ‘Φ250Ηω ±÷”÷ήΤΎΒΡ―”≥ΌΓΘ‘Ύ¥ΥΤΎΦδ»γΙϊCPUΟΜ”–ΤδΥϊ ¬«ι“ΣΉωΘ§‘ρΆυΆυ «¥Π‘ΎΆΘΜζΉ¥Χ§ΒΡΘ®stallΘ©ΓΘΈΣΝΥΗχ¥σΦ““ΜΗω÷±ΙέΒΡ”ΓœσΘ§Έ“Ο«Α―CPUΒΡ“ΜΗω ±÷”÷ήΤΎΩ¥Ής“ΜΟκΓΘΡ«Ο¥Θ§¥”L1 cacheΕΝ»Γ–≈œΔΨΆΚΟœώ «ΡΟΤπΉά…œΒΡ“Μ’≈≤ίΗε÷ΫΘ®3ΟκΘ©ΘΜ¥”L2 cacheΕΝ»Γ–≈œΔ‘ρ «¥”…μ±ΏΒΡ ιΦή…œ»Γ≥ω“Μ±Ψ ιΘ®14ΟκΘ©ΘΜΕχ¥”÷ς¥φ÷–ΕΝ»Γ–≈œΔ‘ρœύΒ±”ΎΉΏΒΫΑλΙΪ¬Ξœ¬»Ξ¬ρΗωΝψ ≥Θ®4Ζ÷÷”Θ©ΓΘ
÷ς¥φ≤ΌΉςΒΡΉΦ»Ζ―”≥Ό «≤ΜΙΧΕ®ΒΡΘ§”κΨΏΧεΒΡ”Π”Ο“‘ΦΑΤδΥϊ–μΕύ“ρΥΊ”–ΙΊΓΘ±»»γΘ§Υϋ“άάΒ”ΎΝ–―ΓΆ®―”≥Ό(CAS)“‘ΦΑΡΎ¥φΧθΒΡ–ΆΚ≈Θ§ΥϋΜΙ“άάΒ”ΎCPU÷ΗΝν‘Λ»ΓΒΡ≥…ΙΠ¬ ΓΘ÷ΗΝν‘Λ»ΓΩ…“‘ΗυΨίΒ±«Α÷¥––ΒΡ¥ζ¬κά¥≤¬≤β÷ς¥φ÷–ΡΡ–©≤ΩΖ÷Φ¥ΫΪ±Μ Ι”ΟΘ§¥”ΕχΧα«ΑΫΪ’β–©–≈œΔ‘Ί»κcacheΓΘ
Ω¥Ω¥L1/L2 cacheΒΡ–‘ΡήΘ§‘ΌΕ‘±»÷ς¥φΘ§ΨΆΜαΖΔœ÷ΘΚ≈δ÷ΟΗϋ¥σΒΡcacheΜρ’Ώ±ύ–¥ΡήΗϋΚΟΒΡάϊ”ΟcacheΒΡ”Π”Ο≥Χ–ρΘ§Μα ΙœΒΆ≥ΒΡ–‘ΡήΒΟΒΫΕύΟ¥œ‘÷χΒΡΧαΗΏΓΘ»γΙϊœκΫχ“Μ≤ΫΝΥΫβ”–ΙΊΡΎ¥φΒΡ÷νΕύ–≈œΔΘ§ΕΝ’ΏΩ…“‘≤Έ‘ΡUlrich DrepperΥυ–¥ΒΡ“ΜΤΣΨ≠ΒδΈΡ’¬ΓΕWhat Every Programmer Should Know About MemoryΓΖΓΘ
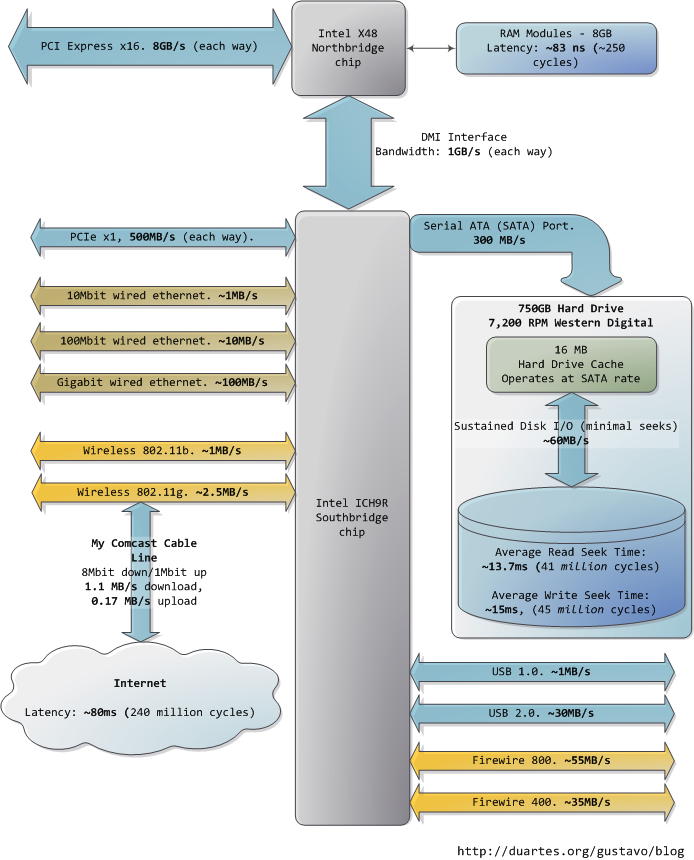
»ΥΟ«Ά®≥ΘΑ―CPU”κΡΎ¥φ÷°ΦδΒΡΤΩΨ±Ϋ–ΉωΖκΓΛ≈Β“ά¬ϋΤΩΨ±Θ®von Neumann bottleneckΘ©ΓΘΒ±ΫώœΒΆ≥ΒΡ«ΑΕΥΉήœΏ¥χΩμ‘ΦΈΣ10GB/sΘ§Ω¥Τπά¥ΚήΝν»Υ¬ζ“βΓΘ‘Ύ’βΗωΥΌΕ»œ¬Θ§ΡψΩ…“‘‘Ύ1ΟκΡΎ¥”ΡΎ¥φ÷–ΕΝ»Γ8GBΒΡ–≈œΔΘ§Μρ’Ώ10Ρ…ΟκΡΎΕΝ»Γ100Ή÷
ΫΎΓΘ“≈ΚΕΒΡ «Θ§’βΗωΆΧΆ¬ΝΩ÷Μ «άμ¬έΉν¥σ÷ΒΘ®ΆΦ÷–ΤδΥϊ ΐΨίΈΣ ΒΦ ÷ΒΘ©Θ§Εχ«“ «Ηυ±Ψ≤ΜΩ…Ρή¥οΒΫΒΡΘ§“ρΈΣ÷ς¥φΩΊ÷ΤΒγ¬ΖΜα“ΐ»κ―”≥ΌΓΘ‘ΎΉωΡΎ¥φΖΟΈ ±Θ§Μα”ωΒΫΚήΕύΝψ
…ΔΒΡΒ»¥ΐ÷ήΤΎΓΘ±»»γΒγΤΫ–≠“ι“Σ«σΘ§‘Ύ―ΓΆ®“Μ––ΓΔ―ΓΆ®“ΜΝ–ΓΔ»ΓΒΫΩ…ΩΩΒΡ ΐΨί÷°«ΑΘ§–η“Σ”–“ΜΕ®ΒΡ–≈Κ≈Έ»Ε® ±ΦδΓΘ”…”Ύ÷ς¥φ÷– Ι”ΟΒγ»ίά¥¥φ¥Δ–≈œΔΘ§ΈΣΝΥΖά÷Ι“ρΉ‘»Μ
Ζ≈ΒγΕχΒΦ÷¬ΒΡ–≈œΔΕΣ ßΘ§ΨΆ–η“Σ÷ήΤΎ–‘ΒΡΥΔ–¬ΥϋΥυ¥φ¥ΔΒΡΡΎ»ίΘ§’β“≤¥χά¥ΕνΆβΒΡΒ»¥ΐ ±ΦδΓΘΡ≥–©Ν§–χΒΡΡΎ¥φΖΟΈ ΖΫ ΫΩ…ΡήΜα±»ΫœΗΏ–ßΘ§ΒΪ»‘»ΜΨΏ”–―” ±ΓΘΕχΡ«–©ΥφΜζ
ΒΡΡΎ¥φΖΟΈ ‘ρœϊΚΡΗϋΕύ ±ΦδΓΘΥυ“‘―”≥Ό «≤ΜΩ…±ήΟβΒΡΓΘ
ΆΦ÷–œ¬ΖΫΒΡΡœ«≈Ν§Ϋ”ΝΥΚήΕύΤδΥϊΉήœΏΘ®»γΘΚPCI-E, USBΘ©ΚΆΆβΈß…η±ΗΘΚ
 |
|


